1. Introduction / Background
We propose a multimodal ML pipeline to process de-identified urology visit artifacts (scanned reports and images) and train supervised models that generate reports similar in style and content to the originals. The task involves aligning textual reports with corresponding images so that, when given an unseen study, the system can output a coherent, clinically styled draft.
Multimodal medical models are advancing rapidly: Google’s MedGemma (Hugging Face) is designed for medical text–image comprehension and shows strong benchmark performance [3], [9], making it a promising base model for urology workflows. We additionally explored Qwen2.5-VL with the FLARE-2025 medical adapter, which demonstrated superior performance in our preliminary experiments and became our primary vision-language model. BiomedCLIP [5] demonstrates effective biomedical vision–language alignment and provides a robust framework for evaluating image-text correspondence in medical contexts. For clinical text encoding and embedding tasks, ClinicalBERT remains a strong encoder [6], though our final pipeline prioritized BiomedCLIP’s multimodal embeddings for evaluation.
Some scans contain text burned into images (faxed forms, typed overlays). To make these usable, we will apply OCR preprocessing [7], [8]. For this checkpoint, we deferred OCR integration to focus on end-to-end vision-language model training, as modern VLMs like Qwen2.5-VL are designed to extract visual information directly from images without requiring explicit text extraction. OCR will be integrated in future iterations to improve numerical measurement accuracy.
Note: While our proposal and midterm checkpoint outlined LLaVA-Med as a candidate model, our implementation prioritized MedGemma and Qwen2.5-VL (FLARE-25) as our primary report generation models based on recent literature demonstrating their superior performance on medical vision-language tasks. BiomedCLIP replaced ClinicalBERT for our evaluation framework, as its vision-language alignment capabilities better suited our need to assess both clinical accuracy (report-to-report similarity) and image grounding (report-to-image alignment). These changes allowed us to leverage state-of-the-art medical multimodal architectures while maintaining our core objective of automated ultrasound report generation.
Dataset
We begin with 663 studies, each a subfolder containing:
/scans/- PNG images (some with annotations)report.txt- Corresponding urology report
This provides paired multimodal data: images aligned with reports.
2. Problem Definition
Problem: Given urology studies (ultrasound scans), train supervised multimodal models that generate clinical reports matching the style, structure, and clinical content of radiologist-authored reference reports.
Motivation: Radiologists interpret ultrasound scans and draft detailed reports that urologists rely on for patient care decisions. This process is time-consuming and cognitively demanding, especially at high volume. An assistive system that generates a first-pass draft could streamline workflow [1], [2], reducing the time radiologists spend on routine documentation while maintaining clinical accuracy. The intended use is assistive: radiologists would review, verify, and edit AI-generated drafts rather than starting from scratch, potentially improving reporting consistency, reducing turnaround time, and accelerating clinical decision-making. This system is designed to augment clinician workflow, not replace radiologist expertise or clinical judgment.
3. Methods
Preprocessing
Image Processing: All ultrasound scans were resized to 224×224 resolution and converted to RGB format to ensure compatibility with vision-language model encoders. Images with near-zero variance (effectively blank frames) were filtered out to remove non-diagnostic content. This preprocessing pipeline was applied uniformly across all 663 studies to maintain consistency for both model training and BiomedCLIP embedding extraction.
Report Processing: Ground truth radiology reports were used as-is from the Advanced Urology dataset without additional text normalization or cleaning. Reports were structured in the standard AU format with sections including Study, Procedures, Indication, Comparison, Technique, Findings, and Impressions.
Model-Specific Considerations:
-
Qwen2.5-VL (with FLARE-25 adapter): Images were preprocessed according to Qwen’s native vision encoder requirements, with the model handling additional internal normalization during inference.
-
MedGemma: Utilized the same standardized 224×224 RGB images, ensuring fair comparison between the two architectures. Status: Preprocessing pipeline is complete and consistent across all splits (train/val/test). No OCR extraction or additional text augmentation was performed, as both models operate end-to-end on the raw image-report pairs.
Models Implemented
BiomedCLIP Embeddings (Unsupervised Preprocessing Component)
-
Purpose: Extract domain-specific multimodal embeddings from ultrasound images and clinical reports to enable quantitative evaluation of report generation quality.
-
Implementation: We used the pretrained BiomedCLIP vision-language model to encode each ultrasound study’s images and ground truth reports into a shared embedding space. Image embeddings were computed by averaging frame-level features across all scans in a study, while text embeddings captured the semantic content of radiology reports.
-
Justification: BiomedCLIP was trained on large-scale medical image-text pairs, making it well-suited for assessing clinical accuracy and image grounding in ultrasound report generation. Unlike general-purpose CLIP models, BiomedCLIP captures domain-specific patterns such as anatomical structures, imaging artifacts, and clinically relevant visual features that are critical for evaluating ultrasound reports.
-
Status: Successfully extracted and saved embeddings for all 663 ultrasound studies (train/val/test splits). These embeddings establish the foundation for our evaluation framework: we compute cosine similarity between (1) generated reports and ground truth reports (clinical accuracy), and (2) generated reports and ultrasound images (image grounding). This quantitative assessment complements traditional NLP metrics and provides insight into how well models align their outputs with both clinical standards and actual imaging findings.
MedGemma Vision–Language Model (Supervised Model)
MedGemma takes preprocessed ultrasound images as input and generates a clinical-style text report for each study.
-
Purpose: We want to evaluate out-of-the-box performance of a pretrained multimodal medical model on urology data. It would also need no additional supervision or fine-tuning. Our goal was to see whether MedGemma could generalize to the urology ultrasound data and be able to generate reports that have comparable meaning to the original ones.
-
Justification: MedGemma is specifically trained for medical image captioning and text generation, making it more suitable than generic LLMs. Its architecture supports long-context multimodal comprehension—ideal for multi-scan studies. Unlike simple CNN-based approaches, MedGemma can maintain anatomical context and is able to generate natural-language clinical interpretations. It is also pretrained on clinical vocabulary so it uses wording that is similar to that of a real urology report written by a doctor.
-
Implementation: Each study’s image set was passed through the MedGemma encoder–decoder via Hugging Face. The model then produced text reports and these outputs were saved under /medgemma_reports/. These outputs are the basis of our evaluation which we did using semantic and lexical similarity metrics.
Qwen 2.5VL + FLARE Medical Adapter + AU QLoRA
-
Purpose: We used Qwen 2.5VL as our third model since it is trained on broad and open domain visual and linguistic datasets. However, rather than using the base model directly, we built upon the FLARE25-Qwen2.5VL checkpoint—a medical-domain adapter that fine-tunes Qwen for clinical imaging tasks. On top of this, we applied QLoRA (Quantized Low-Rank Adaptation) to further fine-tune the model specifically on Advanced Urology ultrasound studies. Our goal was to evaluate whether this stacked approach—general vision-language foundation, medical domain adaptation, then institution-specific fine-tuning—could produce ultrasound reports that are clinically meaningful and outperform other domain-specific models.
-
Justification: Qwen 2.5VL is specifically skilled at producing more concise and coherent sentences, which we could see through its BLEU, ROUGE-L, METEOR, and TF-IDF scores. Its vision encoder was able to effectively handle multi-image context, which is important for ultrasound studies that contain multiple frames per exam. Qwen also had higher clinical term F1 and recall, showing that it captures more findings and misses fewer key terms than MedGemma. It also demonstrated stronger semantic alignment with both ground truth reports and the underlying images. Additionally, Qwen’s variance across all evaluation metrics was quite low—a consistency that MedGemma didn’t achieve.
-
Implementation: We started with the base Qwen2.5-VL-7B-Instruct model and loaded the FLARE25-Qwen2.5VL adapter from HuggingFace, which was then merged into the base weights. We then applied QLoRA training on our AU dataset (530 training samples, 66 validation samples) for 3 epochs, targeting the attention projection layers (q_proj, k_proj, v_proj, o_proj) with rank 32 and alpha 64. During training, label masking ensured the model only learned from the assistant responses (the actual reports), not the instruction prompts. For inference, all preprocessed ultrasound images for each study were passed to the model along with a structured instruction prompt requesting a clinical report in AU’s format. The model generated one report per study, saved to /reports/medqwen_au/.
4. Results & Discussion
Visualizations
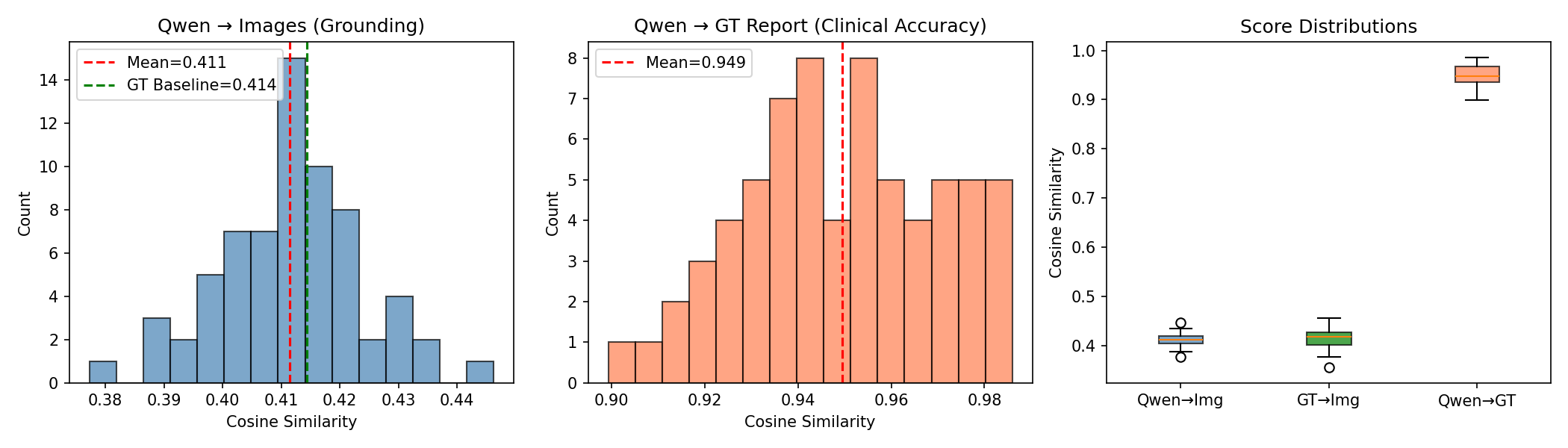
Qwen:
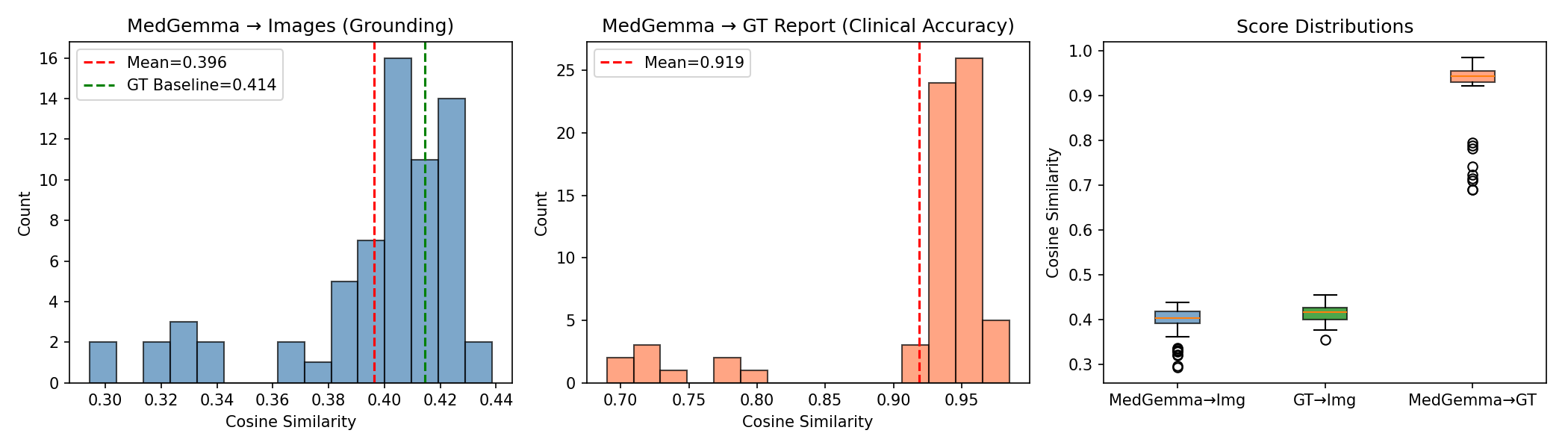
MedGemma:
Comparison Plots:
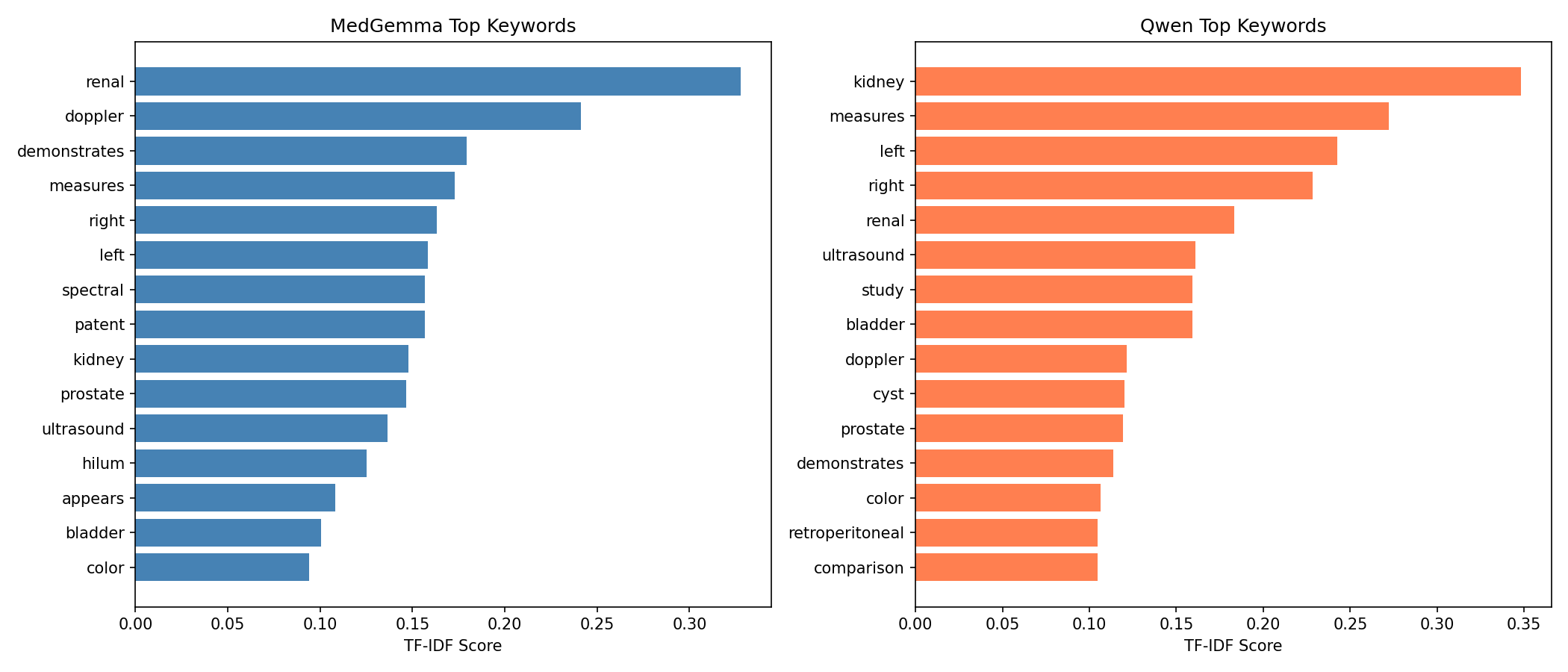
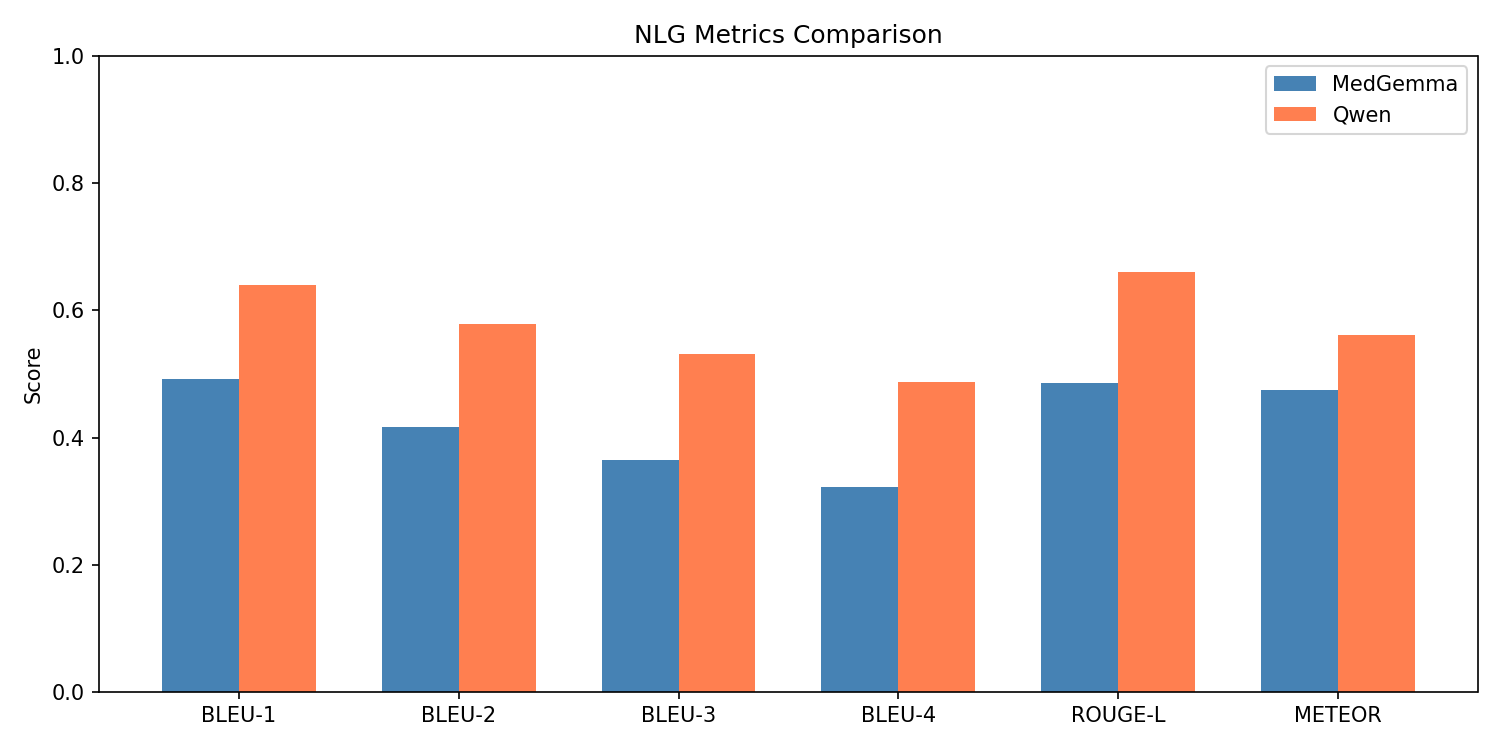
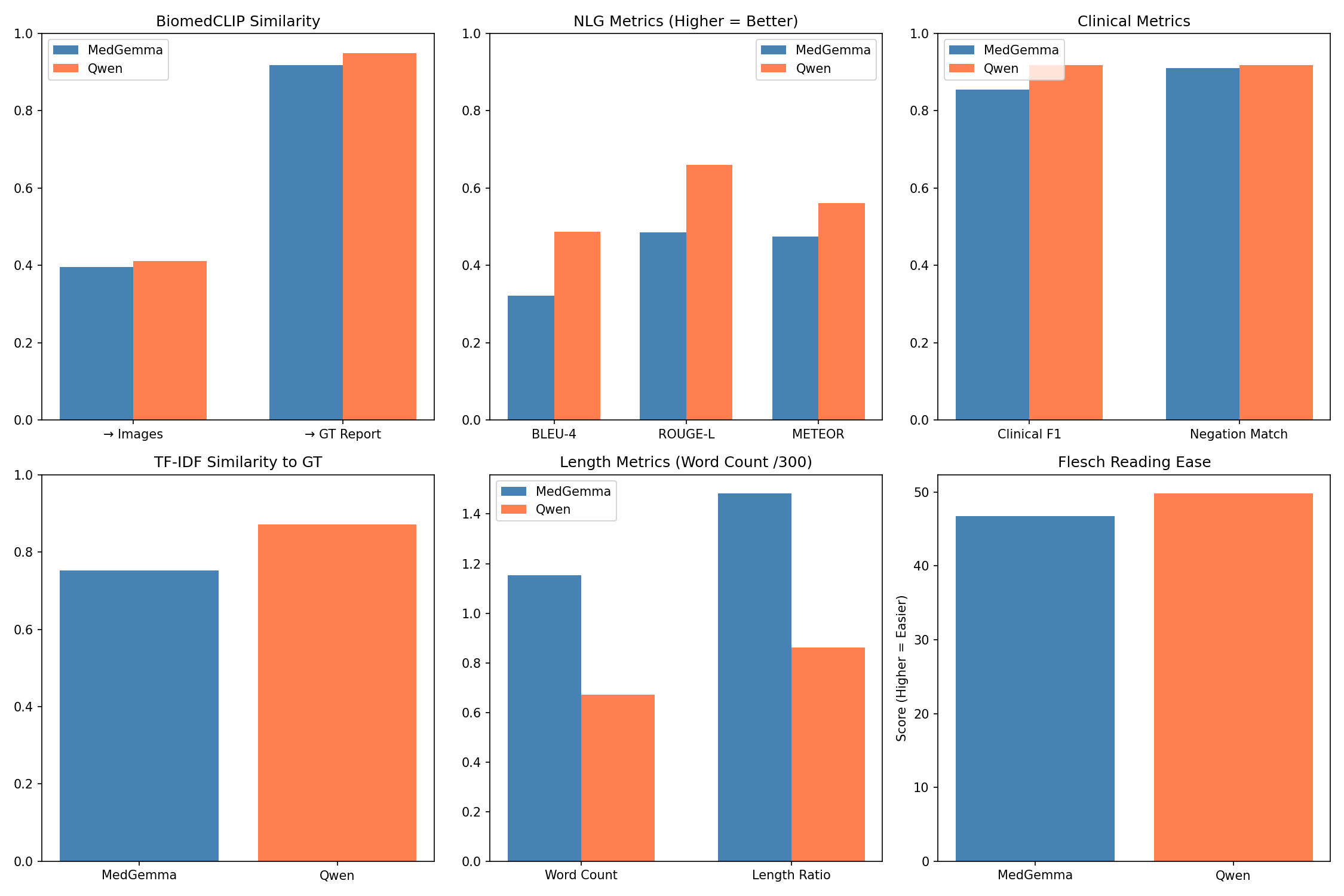
Quantitative Metrics + Analysis:
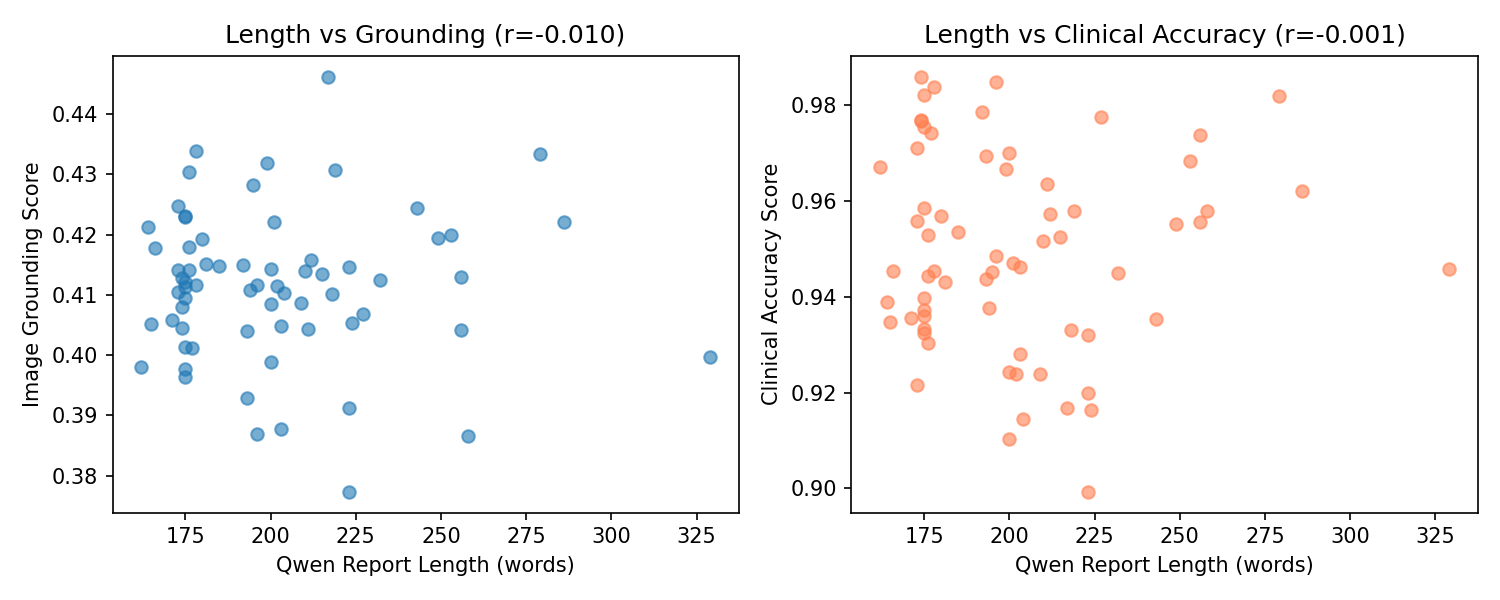
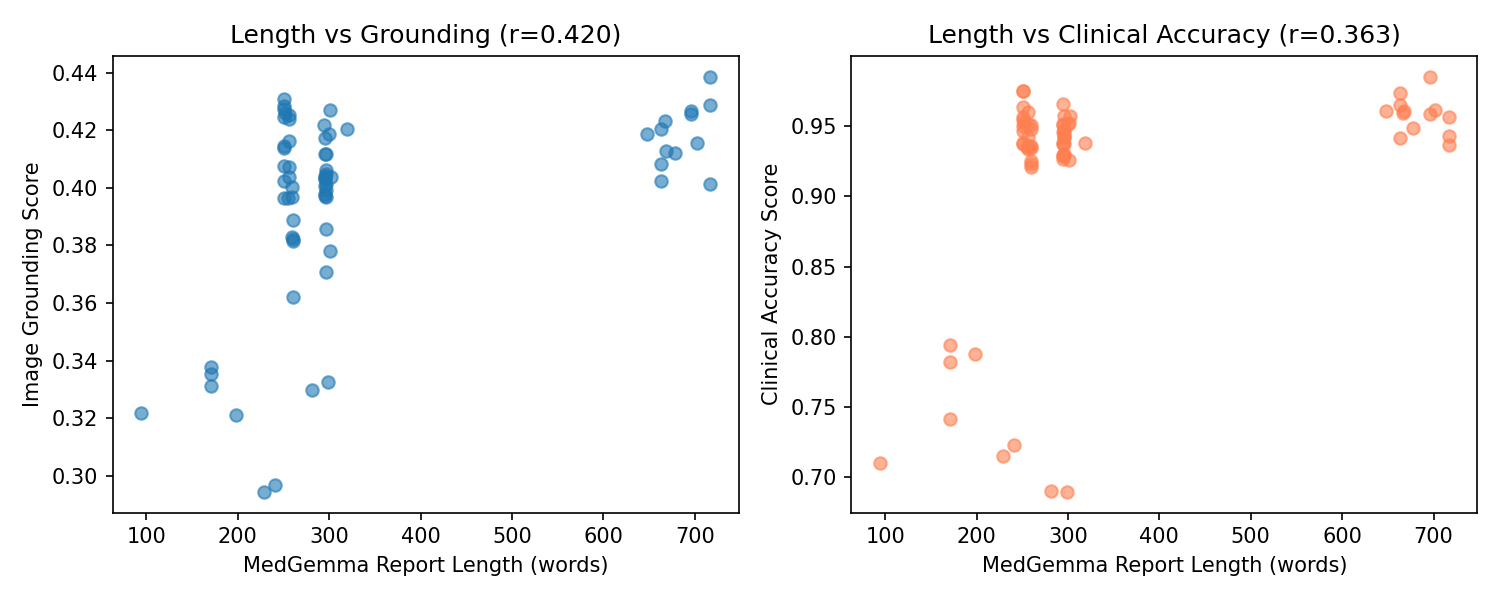
Across all quantitative evaluations, the three models—MedGemma, Qwen2.5-VL (with FLARE-2025 and QLoRA fine-tuning), and the BiomedCLIP embedding framework showed distinct performance characteristics reflecting their architectural differences and training dynamics. BiomedCLIP, used solely as an evaluation backbone, produced stable and clinically meaningful multimodal embeddings that allowed us to quantify both clinical accuracy (report-to-report similarity) and image grounding (report-to-image similarity). The ground-truth reports achieved an image-grounding similarity of 0.414, which is an upper bound of how well a report can align with the ultrasound content. On the other hand, MedGemma achieved an average image-grounding score of 0.396, showing mostly inconsistent alignment with what is shown in the scans. Qwen2.5-VL was actually closer to the ground-truth limit, with an average grounding score of 0.4115, suggesting that its generated reports are similar to the research of radiologists.
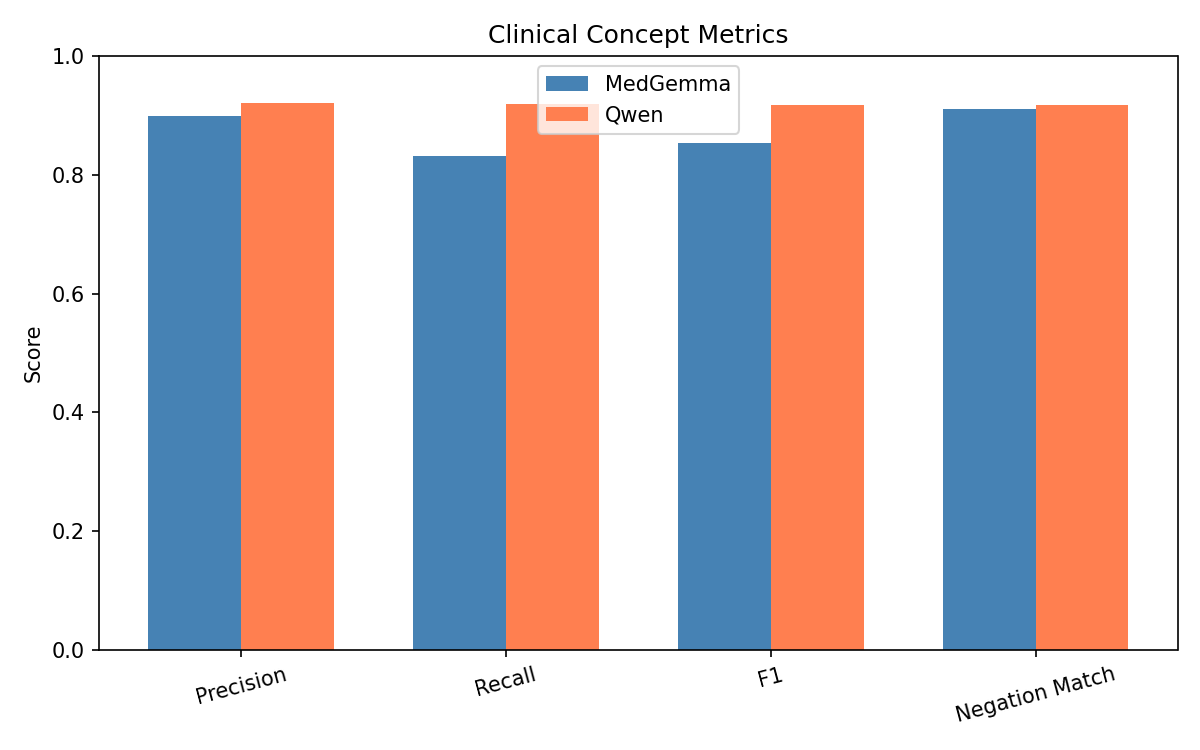
Referencing the BiomedCLIP cosine similarity plot between generated and ground-truth reports, MedGemma produced a mean score of 0.919, with a wide variance and a tail of lower-performing outputs. Qwen2.5-VL achieved a higher and more stable mean similarity of 0.949, highlighting tighter semantic alignment and far fewer deviations from the essential findings in the reference reports. Clinical term extraction metrics reinforced this pattern: MedGemma reached a clinical term F1-score of 0.8543 and a recall of 0.8310, whereas Qwen2.5-VL reached F1 = 0.9179 and recall = 0.9189, demonstrating that Qwen captured more of the findings, terminology, and organ-specific descriptors mentioned in the ground-truth reports.
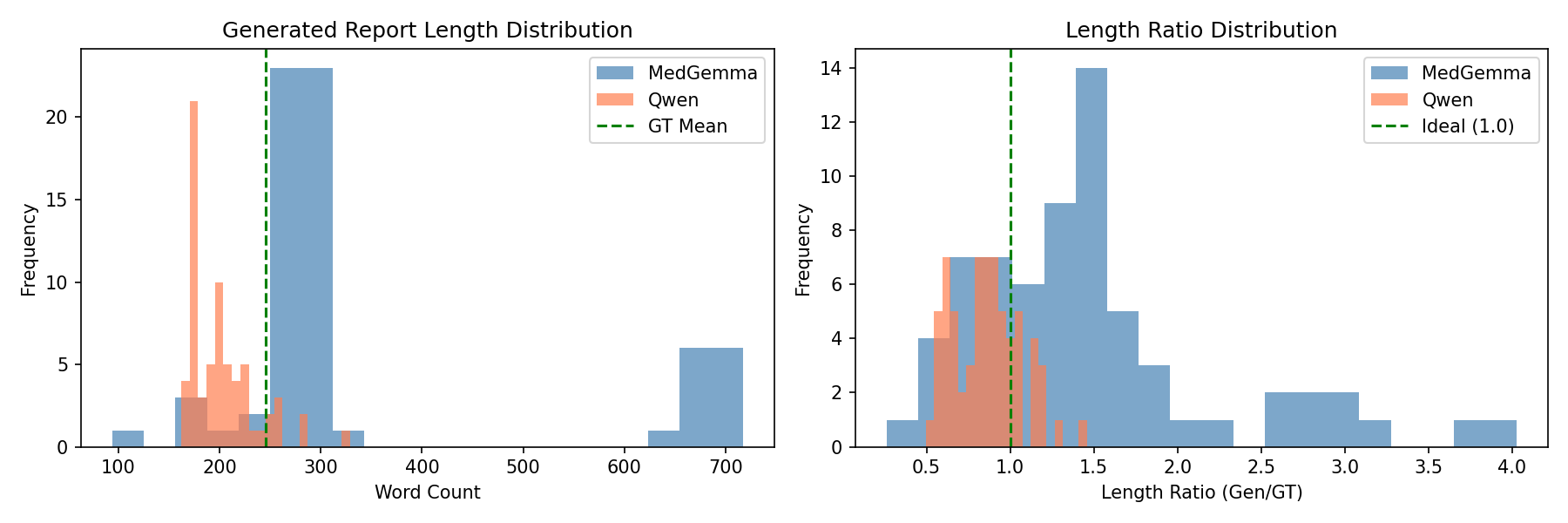
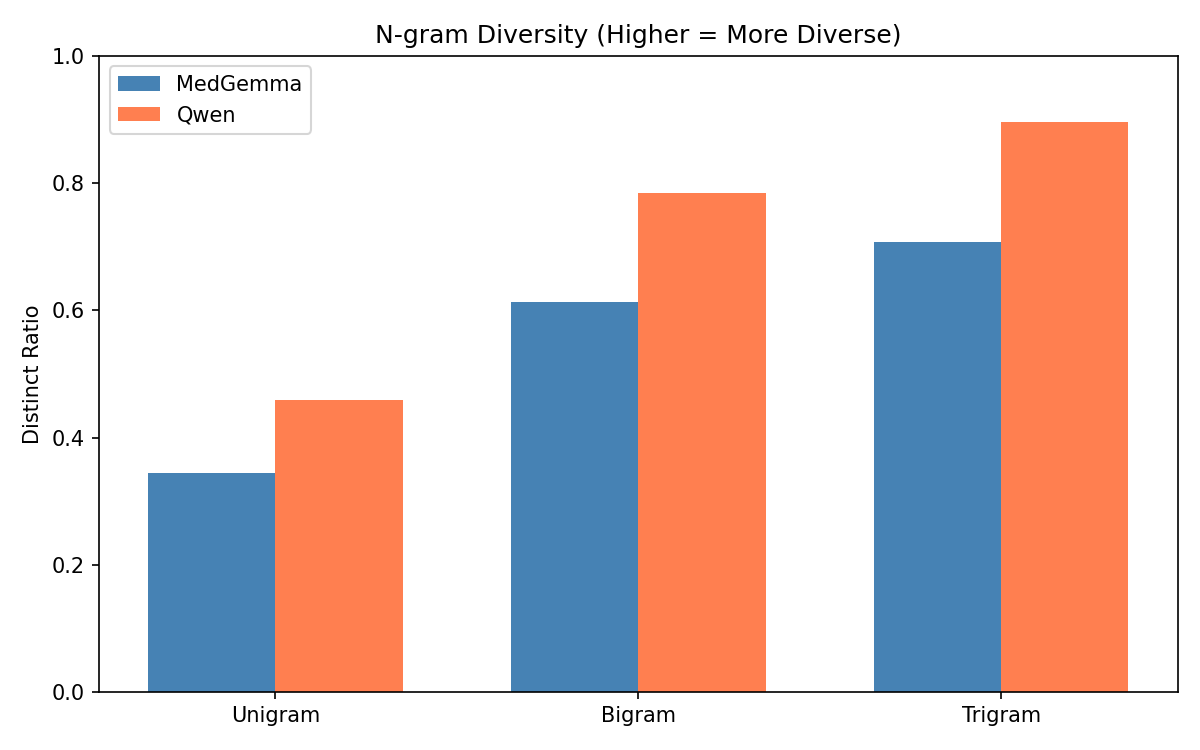
Also, MedGemma generated reports that were nearly 50% longer than the ground truth (average 346 words), with a high repetition rate (0.387) and lower trigram diversity (Distinct-3 = 0.708). These quantitative trends match the scatterplots showing that MedGemma’s performance correlated with the longer report length, along with more padded outputs tended to score better. Therefore, the model compensates for uncertainty by producing verbose text. On the other hand, Qwen2.5-VL produced shorter, more efficient reports (average 202 words) with far lower repetition (0.215) and higher lexical diversity (Distinct-3 = 0.896), indicating more concise and targeted descriptions while still maintaining semantic completeness. These quantitative behaviors reflect the training dynamics where MedGemma required 30 epochs and reached very low training loss consistent with overfitting, while Qwen converged cleanly in just 3 epochs with evaluation loss closely tracking training loss, indicating strong generalization to unseen studies.
Together, these quantitative results show that BiomedCLIP provides a robust framework for evaluating multimodal alignment, MedGemma demonstrates partial but unstable generalization with verbose and repetitive tendencies, and Qwen2.5-VL consistently delivers the strongest results across clinical accuracy, visual grounding, clinical terminology recall, lexical efficiency, and overall stability.
Next Steps
-
Clinical Validation with AU Radiologists: Present generated reports from both MedGemma and Qwen2.5-VL to Advanced Urology staff radiologists for expert clinical assessment. This human evaluation will provide crucial insights that automated metrics cannot capture, including: (1) diagnostic correctness and clinical relevance, (2) adherence to AU reporting standards and terminology, (3) patient safety concerns (e.g., missed findings or dangerous hallucinations), and (4) overall report usability in clinical workflows. Radiologist feedback will help us understand whether quantitative improvements in BiomedCLIP similarity and NLP metrics actually translate to clinically meaningful improvements.
-
OCR Integration for Measurement Accuracy: A critical limitation we observed in both models is inconsistent extraction of precise numerical measurements from ultrasound images (e.g., kidney dimensions, resistive indices, bladder volumes, prostate volumes). We plan to integrate OCR-extracted text as additional input context to improve measurement accuracy in generated reports. - This would involve: (1) extracting on-screen measurements and annotations from ultrasound frames, (2) cleaning and structuring the OCR output, and (3) providing this text alongside images during inference to guide the models toward more precise quantitative reporting.
-
Comprehensive Error Analysis: Using our BiomedCLIP embeddings and similarity metrics, we will conduct systematic error categorization to identify model-specific failure modes. This includes analyzing: (1) anatomical hallucinations (reporting structures not visible in images), (2) measurement inaccuracies (incorrect or missing quantitative values), (3) overly generic findings (lacking study-specific detail), and (4) report structure inconsistencies (deviating from AU format). Understanding these patterns will guide targeted improvements in prompt engineering and fine-tuning strategies.
-
Advanced Fine-Tuning Strategies: Future experiments could explore: (1) layer-selective fine-tuning to preserve general medical knowledge while specializing the vision encoder for ultrasound-specific features, (2) structured prompt engineering with explicit measurement extraction instructions, and (3) curriculum learning strategies that progressively introduce complex multi-organ studies after training on simpler single-structure scans.
-
Multimodal Dataset Enhancement: Building a fully integrated multimodal dataset that combines sequential ultrasound frames, OCR-extracted measurements, Doppler waveforms, and structured radiology reports. This would create (image + OCR → report) training pairs that explicitly connect visual patterns (e.g., hydronephrosis, renal stones) with quantitative measurements and their corresponding clinical descriptions, potentially improving both diagnostic accuracy and report coherence.
References
[1] D. Golden and R. Pilgrim, “MedGemma: Our most capable open models for health AI development,” Google Research, Jul. 09, 2025. https://research.google/blog/medgemma-our-most-capable-open-models-for-health-ai-development/ (accessed Oct. 02, 2025).
[2] C. Li et al., “LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day,” Jun. 2023. doi: https://doi.org/10.48550/arXiv.2306.00890.
[3] S. Zhang et al., “BiomedCLIP: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs,” Jan. 2025. doi: https://doi.org/10.48550/arXiv.2303.00915.
[4] K. Huang, J. Altosaar, and R. Ranganath, “ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission,” Nov. 2020. doi: https://doi.org/10.48550/arxiv.1904.05342.
[5] E. Hsu, I. Malagaris, Y.-F. Kuo, R. Sultana, and K. Roberts, “Deep learning-based NLP data pipeline for EHR-scanned document information extraction,” JAMIA Open, vol. 5, no. 2, Jun. 2022, doi: https://doi.org/10.1093/jamiaopen/ooac045.
[6] J. K. James et al., “Experience With an Optical Character Recognition Search Application for Review of Outside Medical Records,” Mayo Clinic Proceedings: Digital Health, vol. 2, no. 4, pp. 511–514, Aug. 2024, doi: https://doi.org/10.1016/j.mcpdig.2024.08.001.
[7] G. Preda, “From X-rays to Insights: Exploring MedGemma 4B’s Medical Multimodality,” Medium.com, May 25, 2025. https://medium.com/@gabi.preda/from-x-rays-to-insights-exploring-medgemma-4bs-medical-multimodality-ef620a4d8264 (accessed Oct. 03, 2025).
[8] L. Yang et al., “Advancing Multimodal Medical Capabilities of Gemini,” May 2024. doi: https://doi.org/10.48550/arXiv.2405.03162.
[9] K. Saab et al., “Capabilities of Gemini Models in Medicine,” arXiv.org, May 01, 2024. https://arxiv.org/abs/2404.18416 (accessed Oct. 02, 2025).
Gantt Chart
Contribution Table